from pathlib import Path
from dotenv import load_dotenv
#import soundfile as sf
from infer.modules.vc.modules import VC
import os
from os.path import join, dirname
from configs.config import Config
import numpy as np
import pyopenjtalk
from scipy.io import wavfile
from pydub import AudioSegment
from pydub.playback import play
#import librosa
def generate_wav(text_line, filename):
x, sr = pyopenjtalk.tts(text_line, speed=1.0, half_tone=0.0)
wavfile.write("test.wav", sr, x.astype(np.int16))
voice = AudioSegment.from_file("test.wav", format="wav")
play(voice)
_,tgt_opt = vc.vc_single(
1,
"test.wav",
f0_up_key = 0,
f0_method = "rmvpe",
f0_file = None,
file_index = None,
file_index2 = None,
index_rate = 0.75,
filter_radius = 3,
resample_sr = 44100,
rms_mix_rate = 0.25,
protect= 0.33,
)
tgt_sr, audio_opt = tgt_opt
# sf = 44100 # サンプリング周波数 Hz
#y, sr = librosa.core.load('test.wav', sr=44100, mono=True)
#sf.write("new_test.wav", y, sr, subtype="PCM_16")
# sf.write("generation.wav",audio_opt , tgt_sr)
#
wavfile.write(filename, tgt_sr, audio_opt)
os.remove('test.wav')
voice = AudioSegment.from_file(filename, format="wav")
play(voice)
def main():
generate_wav("ありがとうございます", "generation.wav")
if __name__ == "__main__":
# load_dotenv(verbose=True)
dotenv_path = join(dirname(__file__), '.env')
load_dotenv(dotenv_path)
# load_dotenv(".env")
config = Config()
vc = VC(config)
vc.get_vc("kikiV1.pth")
main()
from pathlib import Path
from dotenv import load_dotenv
import soundfile as sf
from infer.modules.vc.modules import VC
import os
from os.path import join, dirname
from configs.config import Config
import tkinter as tk
from tkinter import messagebox, scrolledtext
import pyopenjtalk
import numpy as np
from scipy.io import wavfile
from pydub import AudioSegment
from pydub.playback import play
def generate_audio(text_input, label, scrollbar):
try:
# 読み仮名を取得してラベルに表示
kana = pyopenjtalk.g2p(text_input, kana=True)
label.config(state="normal")
label.delete(1.0, "end")
label.insert("end", "読み仮名: " + kana)
label.config(state="disabled")
# スクロールバーを最下部に移動
scrollbar.set(0.0, 1.0)
# テキストを音声に変換
x, sr = pyopenjtalk.tts(text_input)
wavfile.write("output.wav", sr, x.astype(np.int16))
_,tgt_opt = vc.vc_single(
1,
"output.wav",
f0_up_key = 0,
f0_method = "rmvpe",
f0_file = None,
file_index = None,
file_index2 = None,
index_rate = 0.75,
filter_radius = 3,
resample_sr = 44100,
rms_mix_rate = 0.25,
protect= 0.33,
)
tgt_sr, audio_opt = tgt_opt
sf.write("generation.wav",audio_opt , tgt_sr)
# 生成された音声を再生
voice = AudioSegment.from_file("generation.wav", format="wav")
play(voice)
text_box.delete( 0., "end")
except Exception as e:
# エラーメッセージを表示
messagebox.showerror("Error", str(e))
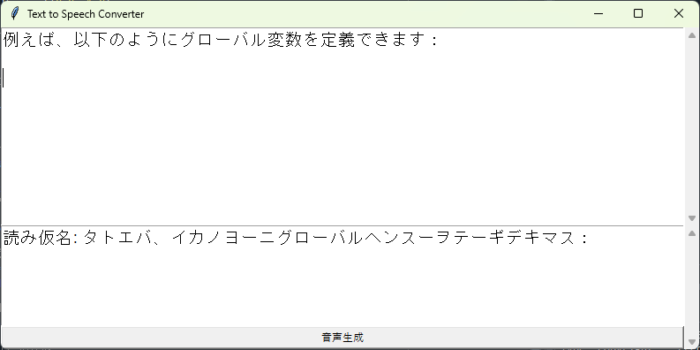
def create_gui():
# Tkinterウィンドウの作成
root = tk.Tk()
root.title("Text to Speech Converter")
# テキストボックスの作成
global text_box
text_box= scrolledtext.ScrolledText(root, width=70, height=10, font=('Arial', 14))
text_box.pack()
# ラベルの作成
kana_label = tk.Text(root, width=70, height=5, font=('Arial', 14))
# スクロールバーの作成
scrollbar = tk.Scrollbar(root, command=kana_label.yview)
scrollbar.pack(side="right", fill="y")
kana_label.config(yscrollcommand=scrollbar.set)
kana_label.pack(fill="both", expand=True)
# ボタンの作成
button = tk.Button(root, text="音声生成", command=lambda: generate_audio(text_box.get("1.0", "end-1c"), kana_label, scrollbar))
button.pack(fill="x")
# ウィンドウを表示
root.mainloop()
if __name__ == "__main__":
# load_dotenv(verbose=True)
dotenv_path = join(dirname(__file__), '.env')
load_dotenv(dotenv_path)
config = Config()
vc = VC(config)
vc.get_vc("kikiV1.pth")
create_gui()