speech_recognitionを使ってマイクに喋りかけて音声をwhisperで文字起こしする
gui のものがあまり見かけなかったので 作ってみました
インストール
pip install SpeechRecognition
pip install -U openai-whisperコード
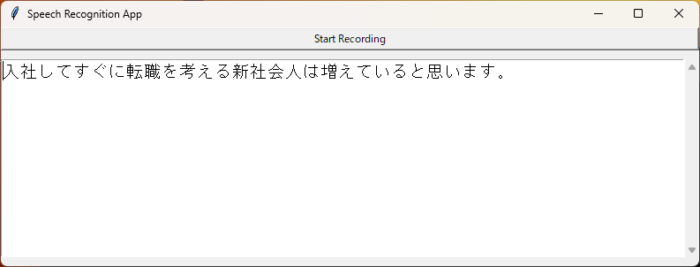
tkinterを使って gui を実現しています。並列処理を行っています
whisperを使っています。テストで Google Speech の変換結果もコンソールに出力しています:
無音になるところで区切っているのでリアルタイムとは行きません ちょっと遅れて変換されます
import tkinter as tk
from tkinter import scrolledtext as tk_scrolledtext
import time
from tkinter import messagebox
import os
import threading
import queue
import speech_recognition as sr
import pyaudio
SAMPLE_RATE = 44100
model_name='medium'
# ハルシネーションで出力される可能性があるテキストを定義
hallucinationTexts = [
"ご視聴ありがとうございました",
"Thanks for watching!",
]
# 録音スレッドの処理
def record_audio():
global recording
global th2
global q
while recording: # recordingがTrueの間、録音を継続
print('record_audio')
with sr.Microphone(sample_rate=SAMPLE_RATE) as source:
r.dynamic_energy_threshold = True # type: bool
r.adjust_for_ambient_noise(source, duration=0.2)
print("[なにか話してください]")
audio = r.listen(source)
#
print("音声処理中 ...")
#
q.put(audio)
print(str(q.qsize())+'Queue')
if not th2.is_alive():
th2 = threading.Thread(target=audio_to_text)
th2.start()
"""
"""
# 音声を文字に変換する関数
def audio_to_text():
global q
print('audio_to_text')
while not q.empty():
print('audio_to_text2')
print(str(q.qsize())+'Queue')
audio2 = q.get()
try:
text = r.recognize_google(audio2, language="ja")
except sr.UnknownValueError:
text = "Google Speech Recognition could not understand audio"
except sr.RequestError as e:
text = "Could not request results from Google Speech Recognition service; {0}".format(e)
print('Google Speech :')
print( f'{text}\n')
try:
text = r.recognize_whisper(audio2, model_name, language="ja", translate=False)
except sr.UnknownValueError:
text = "whisper Speech Recognition could not understand audio"
except sr.RequestError as e:
text = "Could not request results from whisper Speech Recognition service; {0}".format(e)
print('whisper :')
print( f'{text}\n')
if text in hallucinationTexts:
continue
else :
output_text.insert(tk.END, f'{text}\n')
output_text.see(tk.END)
time.sleep(0.1)
#
def start_recording():
global recording
global th
global th2
recording = True
th = threading.Thread(target=record_audio)
th.start()
print("start_recording ...")
th2 = threading.Thread(target=audio_to_text)
th2.start()
# 録音を停止する関数
def stop_recording():
global recording
recording = False
# th.join()
print("stop_recording ...")
# 録音ボタンがクリックされたときの処理
def toggle_recording():
global recording
if recording:
# 録音を停止
stop_recording()
record_button.config(text="Start Recording")
else:
# 録音を開始
start_recording()
record_button.config(text="Stop Recording")
def delete_window():
global recording
global starting
global th
global th2
global q
# 録音を停止
stop_recording()
record_button.config(text="Start Recording")
record_button["state"] = "disabled"
if not starting :
root.destroy()
elif q.empty() and not th.is_alive() and not th2.is_alive():
print(str(q.qsize())+'Queue')
root.destroy()
else:
messagebox.showerror('error', str(q.qsize())+'Queue or running. Wait a minute')
if __name__ == "__main__":
# オーディオキューを作成
q = queue.Queue()
# 録音中かどうかを示すフラグ
recording = False
starting = False
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("Speech Recognition App")
# 録音ボタンを作成
record_button = tk.Button(root, text="Start Recording", command=toggle_recording)
record_button.pack(fill="x")
# 認識結果を表示するテキストウィジェットを作成
output_text = tk_scrolledtext.ScrolledText(root, width=70, height=10, font=('Arial', 14))
output_text.pack(pady=10)
root.protocol("WM_DELETE_WINDOW", delete_window)
print('Loading model...')
global r
r = sr.Recognizer()
with sr.Microphone(sample_rate=SAMPLE_RATE) as source:
#
r.dynamic_energy_threshold = True # type: bool
r.adjust_for_ambient_noise(source, duration=0.2)
audio = r.listen(source)
text = r.recognize_whisper(audio, model_name, language="ja", translate=False)
print('Done')
# GUIを表示
root.mainloop()
仮想環境に対応したバッチファイル
@echo off
call %~dp0\scripts\env_for_icons.bat %*
SET PATH=%PATH%;%WINPYDIRBASE%\PortableGit;%WINPYDIRBASE%\PortableGit\bin
SET PATH=%PATH%;%WINPYDIRBASE%\ffmpeg\bin
If not exist %WINPYDIRBASE%\content mkdir %WINPYDIRBASE%\content
set APP_NAME=openai-whisper
set APP_DIR=%WINPYDIRBASE%\content\%APP_NAME%
echo %APP_DIR%
md %APP_DIR%
cd %APP_DIR%
if not defined VENV_DIR (set "VENV_DIR=%APP_DIR%\venv")
if EXIST %VENV_DIR% goto :activate_venv
::python.exe -m venv "%VENV_DIR%"
python.exe -m venv "%VENV_DIR%" --system-site-packages
if %ERRORLEVEL% == 0 goto :activate_venv
echo Unable to create venv
goto :skip_venv
:activate_venv
call "%VENV_DIR%\Scripts\activate"
::pip install -r requirements.txt
::If exist %WINPYDIRBASE%\content\%APP_NAME%\ goto :skip_cmd
"D:\WinPython\Spyder.exe"
cmd.exe /k
goto :skip_venv
:skip_cmd
::python.exe webui.py
:skip_venv
timeout /t 55
::
cmd.exe /k