ITAコーパスの文章リストを画面に表示させ連続で録音するアプリ。
ITAコーパスの文章リストを画面に表示させ連続で録音するアプリ。文章ごとに録音開始ボタン録音停止ボタンを押さなくてすみます。録音しながら録音した音を再生することもできます。
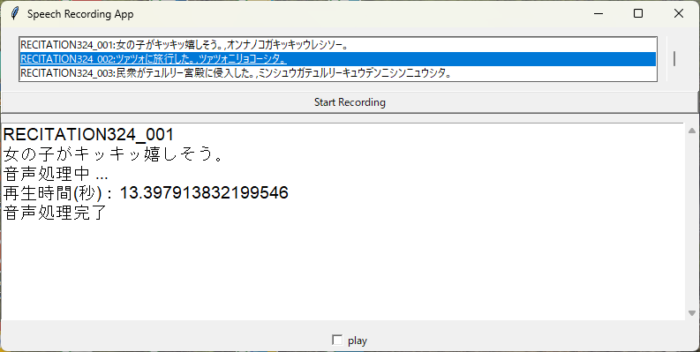
インストールと準備
pip install SpeechRecognition
不足しているライブラリーは自身でインストールしてください
ITAコーパス
GitHub – mmorise/ita-corpus: ITAコーパスの文章リスト
テキストファイルをダウンロードしソースファイルと同じ場所に設置します
文字コードは UTF 8 にしてください
言葉だけのデータでも読み込みができます その場合はファイル名が言葉になります
コード
import tkinter as tk
from tkinter import scrolledtext as tk_scrolledtext
import time
from tkinter import messagebox
import os
from pydub import AudioSegment
from pydub.playback import play
import threading
import speech_recognition as sr
import re
SAMPLE_RATE = 44100
# 録音スレッドの処理
def record_audio():
global recording
global lines
global ix
length = len(lines)
r = sr.Recognizer()
while recording: # recordingがTrueの間、録音を継続
if len(listbox.curselection()) == 0:
ix = None
else:
ix = listbox.curselection()[0]
if ix is None:
record_button.config(text="Start Recording")
stop_recording()
output_text.insert(tk.END, 'stop_recording\n')
break
print('record_audio')
line2 = re.split(':|,|\n', lines[ix])
print("\007")
time.sleep(1.5)
output_text.delete('1.0','end' )
print( f'{ix+1}/{length}\n')
print( f'{line2[0]}\n')
output_text.insert(tk.END, f'{line2[0]}\n')
if len(line2) > 1:
print( f'{line2[1]}\n')
output_text.insert(tk.END, f'{line2[1]}\n')
with sr.Microphone(sample_rate=SAMPLE_RATE) as source:
r.dynamic_energy_threshold = True # type: bool
r.adjust_for_ambient_noise(source, duration=0.2)
print("[なにか話してください]")
audio = r.listen(source)
#
print("音声処理中 ...")
output_text.insert(tk.END, '音声処理中 ...\n')
# write audio to a WAV file
output_filename = dir_path+"/"+line2[0]+".wav" # 出力ファイル名を固定化
sound = AudioSegment(audio.get_raw_data(), sample_width=2, channels=1, frame_rate=SAMPLE_RATE)
newsound = sound + 3
soundtime = newsound.duration_seconds # 再生時間(秒)
print( f'{ix+1}/{length} 録音時間(秒):{soundtime}\n')
output_text.insert(tk.END, f'{ix+1}/{length} 録音時間(秒):{soundtime}\n')
shift_jis_text = output_filename.encode('shift_jis').decode('shift_jis')
print(shift_jis_text) # 変換された文字列の表示
file_handle = newsound.export(shift_jis_text, format="wav")
# with open(output_filename, "wb") as f:
# f.write(audio.get_wav_data())
#
if check_val.get():
# 生成された音声を再生
print("音声再生")
output_text.insert(tk.END, '音声再生\n')
play(newsound)
print("音声再生完了")
output_text.insert(tk.END, '音声再生完了\n')
print("音声処理完了")
output_text.insert(tk.END, '音声処理完了\n')
#
listbox.select_clear(0, tk.END)
time.sleep(3)
ix +=1
if length <= ix:
record_button.config(text="Start Recording")
stop_recording()
output_text.insert(tk.END, 'stop_recording\n')
break
listbox.selection_set(ix)
listbox.see(ix)
"""
"""
#
def start_recording():
global recording
global starting
global th
recording = True
starting = True
th = threading.Thread(target=record_audio)
th.start()
print("start_recording ...")
# 録音を停止する関数
def stop_recording():
global recording
recording = False
# th.join()
print("stop_recording ...")
# 録音ボタンがクリックされたときの処理
def toggle_recording():
global recording
if recording:
# 録音を停止
stop_recording()
record_button.config(text="Start Recording")
else:
# 録音を開始
start_recording()
record_button.config(text="Stop Recording")
def delete_window():
global recording
global th
global starting
# 録音を停止
record_button.config(text="Start Recording")
record_button["state"] = "disabled"
stop_recording()
if not starting :
root.destroy()
elif not th.is_alive() :
root.destroy()
else:
messagebox.showerror('error', 'running. Wait a minute')
def read_file(file_path):
with open(file_path, 'r', encoding='utf-8', errors='ignore') as file: # ファイルをUTF-8エンコーディングで読み込み
return file.readlines()
if __name__ == "__main__":
#
file_path = "recitation_transcript_utf8.txt" # 入力ファイル名を固定化
# file_path = "emotion_transcript_utf8.txt" # 入力ファイル名を固定化
# file_path = "挨拶.txt" # 入力ファイル名を固定化
lines = read_file(file_path)
ix = 0
#
dir_path = 'wav'
os.makedirs(dir_path, exist_ok=True) # 既に存在していてもエラーにならない
# 録音中かどうかを示すフラグ
recording = False
starting = False
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("Speech Recording App")
frame = tk.Frame(root)
frame.pack(padx=20,pady=10,fill="x")
listvar=tk.StringVar()
listvar.set(lines)
listbox=tk.Listbox(frame, width=120, height=3, listvariable=listvar, selectmode='SINGLE')
scrollbar = tk.Scrollbar(frame, orient=tk.VERTICAL, command=listbox.yview)
listbox["yscrollcommand"] = scrollbar.set
scrollbar.pack(side="right")
listbox.pack(side="left",fill="x")
listbox.selection_set(0)
# 録音ボタンを作成
record_button = tk.Button(root, text="Start Recording", command=toggle_recording)
record_button.pack(fill="x")
# 認識結果を表示するテキストウィジェットを作成
output_text = tk_scrolledtext.ScrolledText(root, width=70, height=10, font=('Arial', 14))
output_text.pack(pady=10)
check_val = tk.BooleanVar()
checkbutton = tk.Checkbutton(text="play", variable=check_val)
checkbutton.pack()
root.protocol("WM_DELETE_WINDOW", delete_window)
# GUIを表示
root.mainloop()
仮想環境に関して
次のサイトなどを参考にしてください