過去のデータから株価を予想できるprophetを Anacondaを使わない Windows 環境にインストールする
prophet
pip install convertdate
pip install lunarcalendar
pip install holidays
pip install prophet
サンプル
import os
import yfinance as yf
import pandas as pd
from prophet import Prophet
import matplotlib.pyplot as plt
# 定義
ticker = "NVDA"
file_path = f"{ticker}_stock_data.csv"
def load_and_prepare_data(file_path, ticker):
# データの取得または読み込み
if os.path.exists(file_path):
try:
df = pd.read_csv(file_path)
df['ds'] = pd.to_datetime(df['ds'])
df['y'] = pd.to_numeric(df['y'], errors='coerce')
except ValueError as e:
print(f"Error loading CSV file: {e}")
return fetch_and_save_data(file_path, ticker)
else:
df = fetch_and_save_data(file_path, ticker)
# 欠損値の確認と処理
df.dropna(inplace=True)
return df
def fetch_and_save_data(file_path, ticker):
# 株価データの取得
stock_data = yf.download(ticker, start="2023-01-01", end="2025-01-01")
# 株価データフレームの作成
df = stock_data[['Adj Close']].rename(columns={'Adj Close': 'y'}).reset_index()
df['ds'] = df['Date']
df = df.drop(columns=['Date'])
# データをCSVファイルに保存
df.to_csv(file_path, index=False)
# 保存後に再読み込み
df = pd.read_csv(file_path)
df['ds'] = pd.to_datetime(df['ds'])
df['y'] = pd.to_numeric(df['y'], errors='coerce')
return df
# データのロードと準備
df = load_and_prepare_data(file_path, ticker)
# データ型の確認
print(df.dtypes)
# Prophetモデルのパラメータ設定
params = {
'growth': 'linear',
'changepoints': None,
'n_changepoints': 25,
'changepoint_range': 0.8,
'yearly_seasonality': 'auto',
'weekly_seasonality': 'auto',
'daily_seasonality': 'auto',
'holidays': None,
'seasonality_mode': 'additive',
'seasonality_prior_scale': 10.0,
'holidays_prior_scale': 10.0,
'changepoint_prior_scale': 0.05,
'mcmc_samples': 0,
'interval_width': 0.80,
'uncertainty_samples': 1000,
'stan_backend': None
}
# 3. Prophetモデルの作成
model = Prophet(**params)
model.fit(df)
# 4. 未来のデータフレームを作成して予測
future = model.make_future_dataframe(periods=365, freq='D')
# 土日の予測を除外
future = future[future['ds'].dt.weekday < 5]
forecast = model.predict(future)
# 5. 予測結果の可視化
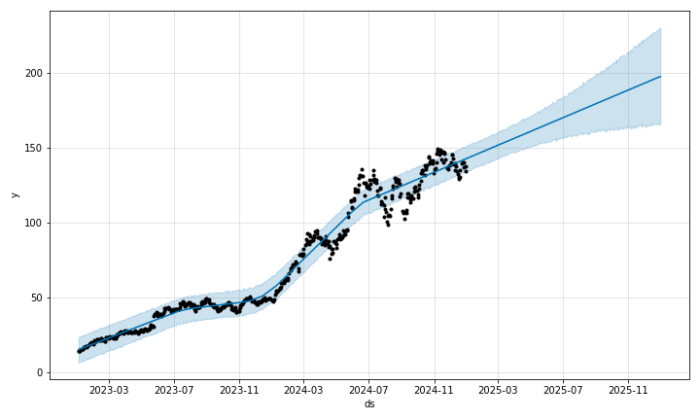
model.plot(forecast)
plt.show()
# 6. 成分のプロット(トレンドのグラフも含む)
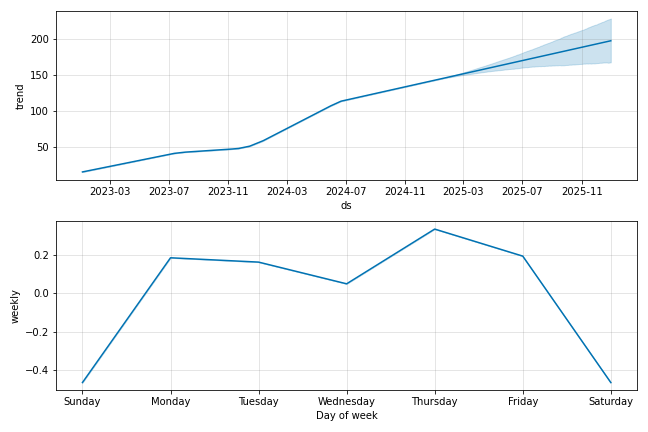
model.plot_components(forecast)
plt.show()
説明
1. インポートと設定
import os
import yfinance as yf
import pandas as pd
from prophet import Prophet
import matplotlib.pyplot as pltos: ファイル操作を行うための標準ライブラリ。yfinance: Yahoo Financeから株価データを取得するライブラリ。pandas: データ操作を行うライブラリ。Prophet: 時系列予測を行うライブラリ。matplotlib.pyplot: グラフ描画を行うライブラリ。
2. 定義とデータの取得
ticker = "NVDA"
file_path = f"{ticker}_stock_data.csv"ticker: 株式のシンボル。ここではNVIDIAを指定。file_path: データを保存するCSVファイルのパス。
3. データのロードと準備
def load_and_prepare_data(file_path, ticker):
if os.path.exists(file_path):
try:
df = pd.read_csv(file_path)
df['ds'] = pd.to_datetime(df['ds'])
df['y'] = pd.to_numeric(df['y'], errors='coerce')
except ValueError as e:
print(f"Error loading CSV file: {e}")
return fetch_and_save_data(file_path, ticker)
else:
df = fetch_and_save_data(file_path, ticker)
df.dropna(inplace=True)
return dfload_and_prepare_data: データを読み込み、必要なら新しく取得して保存。df.dropna(inplace=True): 欠損値を除去。
4. データの取得と保存
def fetch_and_save_data(file_path, ticker):
stock_data = yf.download(ticker, start="2023-01-01", end="2025-01-01")
df = stock_data[['Adj Close']].rename(columns={'Adj Close': 'y'}).reset_index()
df['ds'] = df['Date']
df = df.drop(columns=['Date'])
df.to_csv(file_path, index=False)
df = pd.read_csv(file_path)
df['ds'] = pd.to_datetime(df['ds'])
df['y'] = pd.to_numeric(df['y'], errors='coerce')
return dffetch_and_save_data: yfinanceを使用して株価データを取得し、CSVファイルに保存。
5. モデルのパラメータ設定
params = {
'growth': 'linear',
'changepoints': None,
'n_changepoints': 25,
'changepoint_range': 0.8,
'yearly_seasonality': 'auto',
'weekly_seasonality': 'auto',
'daily_seasonality': 'auto',
'holidays': None,
'seasonality_mode': 'additive',
'seasonality_prior_scale': 10.0,
'holidays_prior_scale': 10.0,
'changepoint_prior_scale': 0.05,
'mcmc_samples': 0,
'interval_width': 0.80,
'uncertainty_samples': 1000,
'stan_backend': None
}各パラメーターの意味:
growth: 成長モデル(’linear’ または 'logistic’)。changepoints: 変化点のリスト。n_changepoints: 変化点の数。changepoint_range: データ内の変化点の割合。yearly_seasonality,weekly_seasonality,daily_seasonality: 季節性の設定。holidays: 休日データ。seasonality_mode: 季節性のモード(’additive’ または 'multiplicative’)。seasonality_prior_scale,holidays_prior_scale,changepoint_prior_scale: 事前分布のスケール。mcmc_samples: MCMCサンプル数。interval_width: 予測区間の幅。uncertainty_samples: 不確実性サンプル数。stan_backend: Stanバックエンド。
6. モデルの作成とフィッティング
model = Prophet(**params)
model.fit(df)Prophet(**params): 指定したパラメーターでモデルを作成。model.fit(df): データフレームを用いてモデルをフィット。
7. 未来のデータフレームの作成と予測
future = model.make_future_dataframe(periods=365, freq='D')
future = future[future['ds'].dt.weekday < 5]
forecast = model.predict(future)model.make_future_dataframe(periods=365): 365日先までの予測データフレームを作成。future = future[future['ds'].dt.weekday < 5]: 土日の予測を除外。model.predict(future): 未来の予測を実行。
8. 予測結果の可視化
model.plot(forecast)
plt.show()model.plot(forecast): 予測結果をプロット。plt.show(): グラフを表示。
9. 成分のプロット
model.plot_components(forecast)
plt.show()model.plot_components(forecast): 予測結果の成分(トレンド、季節性など)をプロット。