CSVファイルから条件に合ったものをSQLで抽出し必要な項目を出力するには ~ Windows
LTSV,JSON,XMLなどのテキストファイルを使用することもありますが、現在もCSVやTSVファイルを扱うことが多いと思います。excelでも抽出はできますが、前ゼロが取れたり、大量のデータでは処理に時間がかかるだけでなく手作業のためミスを誘発する可能性があります。
バッチ処理で使用することを考え、コマンドラインベースで処理できるプログラムを検討します。このようなプログラムはcsv paser(csvパーサー)と呼ばれます。
私のおすすめはtrdsql
Log Parser
Microsoft製のツールでSQLが書けます。日本語対応しています。
https://www.microsoft.com/ja-jp/download/details.aspx?id=24659
からLogParser.msiをダウンロードしてインストールします。
F:\kansi>"D:\Program Files (x86)\Log Parser 2.2\logparser"
Microsoft (R) Log Parser Version 2.2.10
Copyright (C) 2004 Microsoft Corporation. All rights reserved.
使用方法: LogParser [-i:<input_format>] [-o:<output_format>] <SQL query> |
file:<query_filename>[?param1=value1+...]
[<input_format_options>] [<output_format_options>]
[-q[:ON|OFF]] [-e:<max_errors>] [-iw[:ON|OFF]]
[-stats[:ON|OFF]] [-saveDefaults] [-queryInfo]
LogParser -c -i:<input_format> -o:<output_format> <from_entity>
<into_entity> [<where_clause>] [<input_format_options>]
[<output_format_options>] [-multiSite[:ON|OFF]]
[-q[:ON|OFF]] [-e:<max_errors>] [-iw[:ON|OFF]]
[-stats[:ON|OFF]] [-queryInfo]
CSVのヘルプは
F:\kansi>"D:\Program Files (x86)\Log Parser 2.2\logparser" -h -i:csv
入力フォーマット: CSV (CSV 形式)
カンマ区切り値(CSV)を含むテキストファイルを解析します。
FROM シンタックス:
<filename> [, <filename> ...] |
http://<url> |
STDIN
CSV ファイルのパス
パラメータ:
-headerRow ON|OFF : それぞれのファイルの最初のロウを
(フィールド名を含む) ヘッダーとみなします
。 [既定値=ON]
-iHeaderFile <header file path> : ファイルはヘッダーを含みます。
(個々のファイルのヘッダー定義を上書きしま
す。) [既定値=指定されていません。]
-iDQuotes Auto|Ignore : 二重引用符フィールドの動作; Auto:
自動的に二重引用符フィールドを検出します。
; Ignore: フィールド内の二重引用符をそのま
まにします。 [既定値=Auto]
-fixedFields ON|OFF : ログのフィールド数を固定にします。
[既定値=ON]
-nFields <number of fields> : ログのフィールド数
(-1=実行時に検出します。) [既定値=-1]
-dtLines <number of lines> : 実行時にフィールドのデータ型を検出するため
に一定行数読み込みます。 [既定値=10]
-nSkipLines <number of lines> : スキップする先頭からの行数 [既定値=0]
-comment <any string> : スキップするコメント行のプリフィックス文字
列 [既定値=指定されていません。]
-iCodepage <codepage ID> : 入力データのコードページ
(0=システムコードページ, -1=UNICODE)
[既定値=0]
-iTsFormat <timestamp format> : TIMESTAMP フィールドのフォーマット
[既定値=yyyy-MM-dd hh:mm:ss]
-iCheckpoint <checkpoint file> : このファイルにチェックポイント情報を保存し
ます。 [既定値=チェックポイントがありませ
ん。]
F:\kansi>"D:\Program Files (x86)\Log Parser 2.2\logparser" -h -o:csv
出力フォーマット: CSV (CSV 形式)
カンマ区切り値としてフィールドを出力します。
INTO シンタックス:
<filename> | STDOUT | <empty>
empty の場合 STDOUT を使用します。パスに '*' ワイルドカードを指定している場
合は異なるファイルに結果を出力する "Multiplex mode"
が有効になります。ファイル名はワイルドカードの代わりに SELECT
句の最初の値を使用します。
パラメータ:
-headers ON|OFF|AUTO : 最初の行にフィールド名を出力します。; AUTO
の場合は既存のファイルへ追加する際にヘッダー
を出力しません。 [既定値=AUTO]
-oDQuotes ON|OFF|AUTO : フィールドを二重引用符で囲みます。; AUTO
の場合は区切り文字列が含まれている際にのみ囲
みます。 [既定値=AUTO]
-tabs ON|OFF : 値との間にタブを出力します。 [既定値=OFF]
-oTsFormat <timestamp format> : TIMESTAMP フィールドがレンダリングされた形式
[既定値=yyyy-MM-dd hh:mm:ss]
-oCodepage <codepage ID> : 出力データのコードページ
(0=システムコードページ, -1=UNICODE)
[既定値=0]
-fileMode 0|1|2 : 出力ファイルが既に存在する場合の動作
(0=追加, 1=上書き, 2=無視) [既定値=1]
CSVをインプットにしたサンプル
::ヘッダがある場合 logparser -i:CSV -o:CSV "SELECT * FROM a.csv where id='1'" > b.csv
::ヘッダが無い場合 logparser -i:CSV -o:CSV -headerRow:OFF "SELECT * FROM a.csv where Field1='1'" > b.csv
-dtLines=0とするとすべてstringで処理されるので型がうまくいかない場合は利用してください。
Filename,RowNumber,コード,名前,数量,バーコード F:\kansi\yasai.csv,2,TOMATO,トマト,1,4912345000019
結果はfilenameとRowNumberが入るのでcut.exeで対応してください。
::クエリを別ファイルにする場合 logparser -i:CSV -o:CSV file:query.ini > b.csv
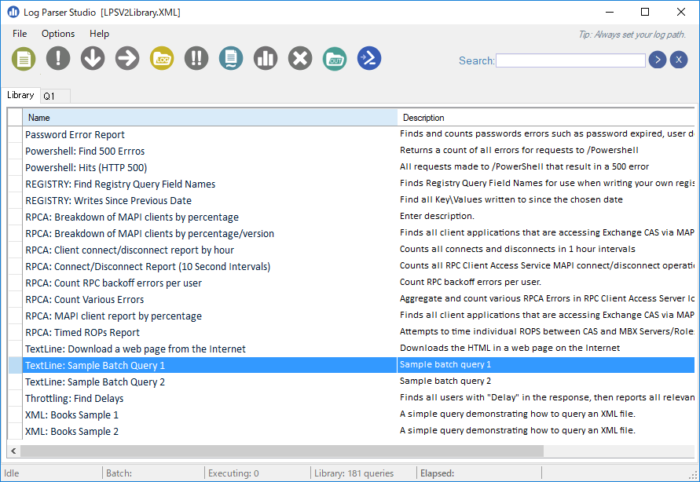
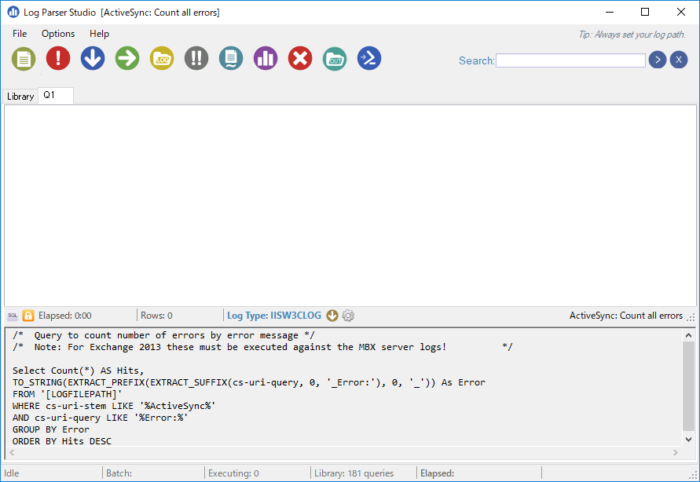
Log Parser Studio
Log Parser StudioはLog ParserのGUI版ですが、Log Parserがインストールされている必要があります。
https://gallery.technet.microsoft.com/Log-Parser-Studio-cd458765
LPSV2.D2.zipを解凍して動かします。
q – Text as Data
コマンドラインベースのツールでCSVをSQLの構文で扱えます。
http://harelba.github.io/q/ja/index.html
pythonベースですが、windowsのインストーラの場合にpythonはインストール不要です。
“C:\Program Files (x86)\q-TextAsData\q.exe" にバイナリがインストールされます。
Pyinstallerで実行ファイルの作成もできます。
SJISの文字コードも扱えます。
ヘルプは
Usage:
q allows performing SQL-like statements on tabular text data.
Its purpose is to bring SQL expressive power to manipulating text data using the Linux command line.
Basic usage is q "<sql like query>" where table names are just regular file names (Use - to read from standard input)
When the input contains a header row, use -H, and column names will be set according to the header row content. If there isn't a header row, then columns will automatically be named c1..cN.
Column types are detected automatically. Use -A in order to see the column name/type analysis.
Delimiter can be set using the -d (or -t) option. Output delimiter can be set using -D
All sqlite3 SQL constructs are supported.
Examples:
Example 1: ls -ltrd * | q "select c1,count(1) from - group by c1"
This example would print a count of each unique permission string in the current folder.
Example 2: seq 1 1000 | q "select avg(c1),sum(c1) from -"
This example would provide the average and the sum of the numbers in the range 1 to 1000
Example 3: sudo find /tmp -ls | q "select c5,c6,sum(c7)/1024.0/1024 as total from - group by c5,c6 order by total desc"
This example will output the total size in MB per user+group in the /tmp subtree
See the help or https://github.com/harelba/q/ for more details.
Options:
-h, --help show this help message and exit
-v, --version Print version
-V, --verbose Print debug info in case of problems
-S SAVE_DB_TO_DISK_FILENAME, --save-db-to-disk=SAVE_DB_TO_DISK_FILENAME
Save database to an sqlite database file
--save-db-to-disk-method=SAVE_DB_TO_DISK_METHOD
Method to use to save db to disk. 'standard' does not
require any deps, 'fast' currenty requires manually
running `pip install sqlitebck` on your python
installation. Once packing issues are solved, the fast
method will be the default.
Input Data Options:
-H, --skip-header Skip header row. This has been changed from earlier
version - Only one header row is supported, and the
header row is used for column naming
-d DELIMITER, --delimiter=DELIMITER
Field delimiter. If none specified, then space is used
as the delimiter.
-t, --tab-delimited
Same as -d <tab>. Just a shorthand for handling
standard tab delimited file You can use
CSVをインプットにしたサンプル
[in1.txt]
4911760003058,x,0,005,a,AA ,AAAA 1279 ,99
4911760003058,x,1,005,b,AA ,AAAA 1280 ,99
[keitai.csv]
03,Book
99,ETC
q -d , --as-text -eShift-JIS "select c4,c6,c7,c8 from in1.txt where c3='0'" >in2q.txt q -d , --as-text -eShift-JIS "SELECT u.*,h.c2 FROM in2q.txt as u LEFT JOIN keitai.csv as h ON(u.c4=h.c1)" > in3q.txt
trdsql
コマンドラインベースのツールでCSVをSQLの構文で扱えます。go言語ベースですが、こちもgo言語のインストールは不要です。
https://github.com/noborus/trdsql/releases
64ビットは trdsql_windows_amd64.zip
解凍するだけです。
ヘルプは
Usage: trdsql [OPTIONS] [SQL(SELECT...)]
Options:
-config string
Configuration file location.
-db string
Specify db name of the setting.
-dblist
display db information.
-debug
debug print.
-driver string
database driver. [ mysql | postgres | sqlite3 ]
-dsn string
database connection option.
-help
display usage information.
-icsv
CSV format for input.
-id string
Field delimiter for input. (default ",")
-ig
Guess format from extension.
-ih
The first line is interpreted as column names(CSV only).
-ijson
JSON format for input.
-iltsv
LTSV format for input.
-is int
Skip header row.
-oat
ASCII Table format for output.
-ocsv
CSV format for output. (default true)
-od string
Field delimiter for output. (default ",")
-oh
Output column name as header.
-ojson
JSON format for output.
-oltsv
LTSV format for output.
-omd
Mark Down format for output.
-oraw
Raw format for output.
-ovf
Vertical format for output.
-q string
Read query from the provided filename.
-version
display version information.
CSVをインプットにしたサンプル
trdsql "select c4,c6,c7,c8 from in1.txt where c3='0'" >in2q.txt trdsql "SELECT u.*,h.c2 FROM in2t.txt as u LEFT JOIN keitai.csv as h ON(u.c4=h.c1)" > in3q.txt
textql
コマンドラインベースのツールでCSVをSQLの構文で扱えます。go言語ベースでgo言語のインストールが必要です。
https://github.com/dinedal/textql
clone or downloadでdownloadします
実行ファイルが配布されていないのですがコンパイルするには、git,gccがあるとよいです。
https://github.com/git-for-windows/git/releases/tag/v2.23.0.windows.1
PortableGit-2.23.0-32-bit.7z.exe
PortableGit-2.23.0-64-bit.7z.exe
解凍してpathを通します
msys32
https://sourceforge.net/projects/msys2/
インストールしたあとgcc.exeに通します
go get -u github.com/dinedal/textql/…
でビルドします
ヘルプは
Usage of textql:
textql [-console] [-save-to path path] [-output-file path] [-output-dlm delimter] [-output-header] [-pretty] [-quiet] [-header] [-dlm delimter] [-sql sql_statements] [path ...]
-console
After all statements are run, open SQLite3 REPL with this data
-dlm string
Input delimiter character between fields -dlm=tab for tab, -dlm=0x## to specify a character code in hex (default ",")
-header
Treat input files as having the first row as a header row
-output-dlm string
Output delimiter character between fields -output-dlm=tab for tab, -dlm=0x## to specify a character code in hex (default ",")
-output-file string
Filename to write output to, if empty no output is written (default "stdout")
-output-header
Display column names in output
-pretty
Output pretty formatting
-quiet
Surpress logging
-save-to string
SQLite3 db is left on disk at this file
-sql string
SQL Statement(s) to run on the data
-version
Print version and exit
CSVをインプットにしたサンプル
textql -sql "select c3,c5,c6,c7 from in1 where c2='0'" in1.txt>in2e.txt textql -sql "SELECT u.*,h.c1 FROM in2e as u LEFT JOIN keitai as h ON(u.c3=h.c0)" in2e.txt keitai.csv> in3e.txt
csvq
コマンドラインベースのツールでCSVをSQLの構文で扱えます。go言語ベースですが、こちもgo言語のインストールは不要です。
https://github.com/mithrandie/csvq
https://github.com/mithrandie/csvq/releases
windows版は
csvq-v1.11.5-windows-386.tar.gz
csvq-v1.11.5-windows-amd64.tar.gz
をダウンロードしてください。
SJISの文字コードも扱えます。
ヘルプは
NAME:
csvq - SQL-like query language for csv
https://mithrandie.github.io/csvq
USAGE:
csvq [options] [subcommand] [query|argument]
VERSION:
Version 1.11.5
SUBCOMMANDS:
fields Show fields in a file
calc Calculate a value from stdin
syntax Print syntax
check-update Check for updates
help, h Shows a list of commands or help for one command
OPTIONS:
--repository PATH, -r PATH directory PATH where files are located
--timezone value, -z value default timezone (default: "Local")
--datetime-format value, -t value datetime format to parse strings
--ansi-quotes, -k use double quotation mark as identifier enclosure
--wait-timeout value, -w value limit of the waiting time in seconds to wait for locked files to be released (default: 10)
--source FILE, -s FILE load query or statements from FILE
--import-format value, -i value default format to load files (default: "CSV")
--delimiter value, -d value field delimiter for CSV (default: ",")
--delimiter-positions value, -m value delimiter positions for FIXED
--json-query QUERY, -j QUERY QUERY for JSON
--encoding value, -e value file encoding (default: "AUTO")
--no-header, -n import the first line as a record
--without-null, -a parse empty fields as empty strings
--out FILE, -o FILE export result sets of select queries to FILE
--format value, -f value format of query results (default: "TEXT")
--write-encoding value, -E value character encoding of query results (default: "UTF8")
--write-delimiter value, -D value field delimiter for CSV in query results (default: ",")
--write-delimiter-positions value, -M value delimiter positions for FIXED in query results
--without-header, -N export result sets of select queries without the header line
--line-break value, -l value line break in query results (default: "LF")
--enclose-all, -Q enclose all string values in CSV and TSV
--json-escape value, -J value JSON escape type (default: "BACKSLASH")
--pretty-print, -P make JSON output easier to read in query results
--east-asian-encoding, -W count ambiguous characters as fullwidth
--count-diacritical-sign, -S count diacritical signs as halfwidth
--count-format-code, -A count format characters and zero-width spaces as halfwidth
--color, -c use ANSI color escape sequences
--quiet, -q suppress operation log output
--limit-recursion value maximum number of iterations for recursive queries (default: 1000)
--cpu value, -p value hint for the number of cpu cores to be used (default: 1)
--stats, -x show execution time and memory statistics
--help, -h show help
--version, -v print the version
PARAMETERS:
Timezone
Local | UTC
Import Format
CSV | TSV | FIXED | JSON | LTSV
Export Format
CSV | TSV | FIXED | JSON | LTSV | GFM | ORG | TEXT
Import Character Encodings
AUTO | UTF8 | UTF8M | UTF16 | UTF16BE | UTF16LE | UTF16BEM | UTF16LEM | SJIS
Export Character Encodings
UTF8 | UTF8M | UTF16 | UTF16BE | UTF16LE | UTF16BEM | UTF16LEM | SJIS
Line Break
CRLF | CR | LF
JSON Escape Type
BACKSLASH | HEX | HEXALL
CSVをインプットにしたサンプル
del in2c.csv del in3c.csv csvq -e SJIS -E SJIS -l CRLF -n -N -o in2c.csv -f CSV "select c4,c6,c7,c8 from in1c where c3='0'" csvq -e SJIS -E SJIS -l CRLF -n -N -o in3c.csv -f CSV "SELECT u.c1,u.c2,u.c3,u.c4,h.c2 FROM in2c as u LEFT JOIN keitai as h ON(u.c4=h.c1)"
入力ファイルは4文字以上でないとうまくいきません。
Sqliteを利用したアプリが多いのですが、件数が大量でなければインメモリで高速のため利用する価値はあります。個人的には以前は後発のcsvq気に入っていましたが、最近はtrdsqlでシフトjisの読み書きができるようになったのでこちらを使っています。trdsqlはdbのジョインも可能です。
querycsv であればメモリでなくsqlitedbを作って処理できます